Distribuciones de probabilidad
Qué aprenderás en esta sección
En esta sección abordaremos el concepto de concepto de distribuciones de probabilidad, que básicamente son la representación matemática por medio de ecuaciones, de los fenómenos aleatorios presentes en la naturaleza.
Desarrollo
Cuando a un espacio muestral se le asigna una variable aleatoria para cada evento que exista, se hace necesario poder representar las probabilidades asociadas a las variables aleatorias por medio de ecuaciones matemáticas o tabulaciones, algunas veces para poder ver de manera gráfica el comportamiento de las probabilidades o simplemente para obtener parámetros o características que solo podrían ser tratadas por medios matemáticos.
Para ilustrar el concepto vamos a emplear el experimento aleatorio de lanzar dos dados, cuyo espacio muestral es el siguiente.
\[\large S = {(1,1), (1,2), (1,3), (1,4),(1,5),(1,6),(2,1), … , (6,5), (6,6)} \]
Aplicando el concepto de variable aleatoria vista en capítulos previos, a cada evento del espacio muestral podemos asignar un número que pueda describir alguna característica de este experimento, para lo cual usaremos a modo de ejemplo la suma de los dos valores obtenidos en un lanzamiento, es decir si al lanzar los dos dados obtenemos el resultado (1,4) la suma de los dos valores será 5, por lo tanto la mínima suma que puedo obtener es con el resultado (1,1) que es igual a 2 y el máximo valor posible sería el resultado (6,6) igual a 12, por lo que la variable aleatoria designada como la suma de los dos valores de los dados, está comprendida en el rango entre 2 y 12, y su representación sería la siguiente.
\[\large X[(1,1)] = 2 \] \[\large X[(1,2), (2,1)] = 3 \] \[\large X[(1,3), (3,1), (2,2)] = 4 \] \[\large ... \] \[\large X[(6,6)] = 12 \]
Al obtener los eventos compuestos asociados a cada variable aleatoria, podemos proceder con la asignación de las respectivas probabilidades, para lo cual obtendremos lo siguiente.

De la tabla anterior se puede evidenciar como se encuentran distribuidas las probabilidades para todos los posibles valores de la variable aleatoria definida como la suma de los dos resultados de los dados, por lo tanto tal y como se menciona, en esto consiste la distribución de probabilidades y nos permite ver de manera gráfica los resultado.
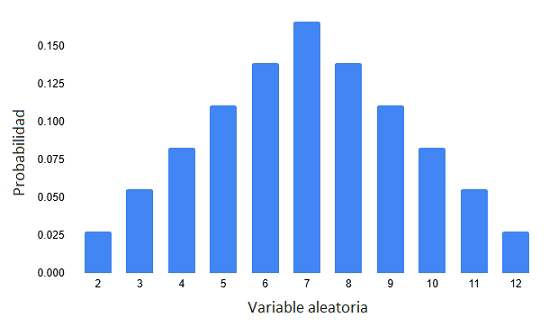
Sin embargo para este ejemplo sencillo solo contamos con una tabulación de valores pero es imprescindible contar con funciones o ecuaciones que nos permitan modelar fenómenos aleatorios, sin embargo dependiendo de la naturaleza de los experimentos o fenómenos se pueden clasificar en funciones discretas o continuas, las cuales veremos a continuación.
Funcion de distribucion discreta
Como su nombre lo indica, se compone de fenómenos o experimentos cuyos resultados son discretos, por ejemplo los lados de un dado, el número de personas en un estudio, la cantidad de artículos vendidos en una tienda, el número de bacterias en una muestra, y en general cualquier experimento en el que los eventos simples no se pueden subdividir, y que solo existe una cantidad finita entre dos valores del espacio, o dicho de una forma mas informal, no existe media persona o media bacteria.
La función de distribución discreta está definida por.
\[\large P(X=x_{k}) = f(x_{k}) \qquad k = 1, 2, 3, \dotsc \]
En donde f(x) será una función de distribución si.
\[\large f(x) \geq 0 \]
\[\large \sum_{x}^{} f(x) = 1 \]
Retomando el ejemplo del lanzamiento de dos dados, se tiene que para cualquier valor de la variable aleatoria la probabilidad es mayor o igual a cero, y la suma de las probabilidades de todos los posibles resultados es igual a 1.
\[\large \sum_{i=n}^{16} f(x) = P(X[(1,1)]) + P(X[(1,2), (2,1)]) + \dotsc + P(X[(6,6)]) = 1 \]
Sin embargo en la mayoría de situaciones no estamos muy interesados en obtener la probabilidad de un valor en específico, en el caso del ejercicio de los dos dados podria tener mas sentido el obtener la probabilidad de que la suma de los dos valores sea en cuánto mucho 5, es decir P(X<= 5) en lugar de la probabilidad de que la suma sea exactamente 5, P(X=5), allí entra en juego la función acumulativa de distribución de probabilidad o en la mayoría de veces llamada simplemente función de distribución, dada por.
\[\large F(x) = P(X \le x) = \sum_{u \le x}^{} f(u) \]
Por lo tanto, para el ejercicio de los dos dados se obtiene la siguiente función de distribución y su respectiva representación gráfica.
\[\large F(x)= \left\{ \begin{array}{lcc} 0 & & -\infty < x \leq 1 \\ \\ F(2) = P(X \leq 2) = \frac{1}{36} & & 1 < x \leq 2 \\ \\ F(3) = P(X \leq 3) = \frac{3}{36} & & 2 < x \leq 3 \\ \\ \vdots & & \vdots \\ \\ F(12) = P(X \leq 12) = 1 & & 11 < x \leq \infty \end{array} \right. \]
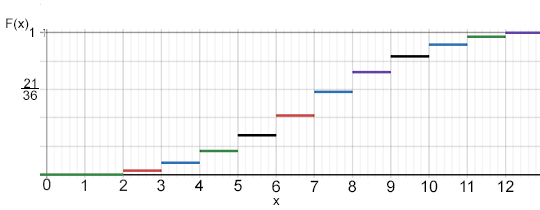
Una función de distribución nos ayuda a comprender mejor el comportamiento de las variables aleatorias y por medio de gráficas detectar más fácilmente comportamientos o características del experimento.
Funcion de distribucion continua
Análogamente al caso discreto, las distribuciones continuas aplican a experimentos cuyos resultados son de índole continuo, por ejemplo medidas de distancia, altura, longitud, medidas de tiempo, precios, pesos, niveles de colesterol y en general todo tipo de resultado en el que entre dos valores diferentes existan infinitos posibles resultados, un ejemplo de ello puede ser las medidas de altura entre una persona y otra, pues entre una medida de 160 cm y 161 cm, existen infinitos valores como 160.1, 160.01, 160.001, etc.
La función de distribución continua f(x) será una función de distribución si.
\[\large f(x) \geq 0 \]
\[\large \int_{-\infty}^{\infty} f(x) \,dx = 1 \]
Y su función acumulativa de distribución será.
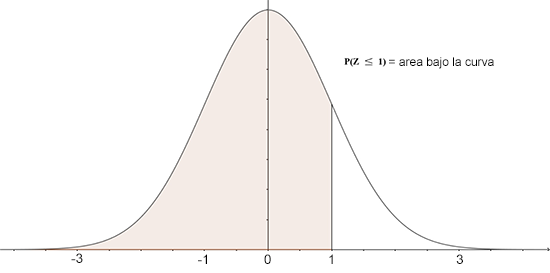
\[\large F(x) = P(X \le x) = P(-\infty < X \le x) = \int_{-\infty}^{x} f(u) \,du \]
Como podemos observar, la función acumulativa de distribución continua, es básicamente el área bajo la curva de la función, delimitada por el rango entre -infinito y el valor de la variable deseada, vista de manera gráfica es.
Distribuciones de probabilidad conjunta
Existen situaciones en las que estamos interesados sobre la distribución o el comportamiento de dos o más variables aleatorias en un mismo experimento, usualmente la naturaleza de las variables son las mismas, es decir todas son discretas o continuas.
Distribución de probabilidad conjunta discreta
Sean X y Y dos variables aleatorias discretas definidas en el espacio muestral S de un experimento. La función masa de probabilidad conjunta p(x, y) se define para cada par de números (x, y) como.
\[\large p(x,y) = P(X=x, Y=y) \]
\[\large \textrm{Debe cumplirse que} \qquad p(x,y) \ge 0 \qquad \sum_{x}^{}\sum_{y}^{} p(x,y) = 1 \]
Retomando el experimento del lanzamiento de los dos dados, vamos a determinar en esta ocasión que cada dado es un experimento independiente uno de otro, es decir, el espacio muestral asociado al lanzamiento del dado 1, será independiente del espacio muestral asociado al lanzamiento del dado 2, por lo tanto tendremos los siguientes dos espacios muestrales.
\[\large S1 = \{1,2,3,4,5,6\} \\ \\ \large S2 = \{1,2,3,4,5,6\} \]
Donde S1 y S2 corresponden a los dados 1 y 2 respectivamente, siendo \( \Large w_{i} \) y \( \Large t_{j} \) los eventos simples respectivos de los espacios S1 y S2, se define el espacio muestral conjunto de la siguiente manera.
\[\large S(w_{i}, t_{j}) , \qquad i=1,2,3,4,5,6; \qquad j=1,2,3,4,5,6 \]
\[\large S = {(1,1), (1,2), (1,3), (1,4), \dotsc , (6.5), (6,6)} \]
Para el espacio muestral S1, vamos a definir la variable aleatoria X que estará relacionada al número de la cara del dado 1 y análogamente definimos de la misma manera la variable aleatoria Y asignada al espacio S2, asumiendo que los dos dados son honestos, y que la probabilidad de cada evento simple de un dado es de ⅙, se tiene que para cualquier posible combinación de resultados del espacio muestral conjunto, la probabilidad de cada evento simple es de 1/36, es decir.
\[\large P(x_{i}, y_{j}) = P(x_{i})*P(y_{j}) = \frac{1}{6} \frac{1}{6} = \frac{1}{36} \]
Por lo tanto la función de distribución de probabilidad conjunta para el presente ejemplo, sería la siguiente.
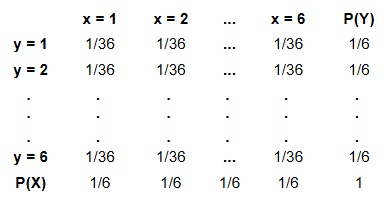
Si quisiéramos saber cual es la probabilidad conjunta de que X sea igual a 1 para todos los valores posibles de Y, es decir la probabilidad de que en ambos experimentos obtenga por lo menos un 1 en el dado 1, sería.
\[\large P(X=1) = \sum_{j=6}^{} P(x_{1}, y_{j}) \\ \\ \large = P(X=1,Y=1) + P(X=1,Y=2) + \dotsc + P(X=1,Y=6) = \frac{1}{6} \]
Si nos percatamos nos daremos cuenta que la probabilidad conjunta obtenida corresponde a la probabilidad aislada de lanzar solo el dado 1 y obtener un 1, esto se debe a la independencia de los dos experimentos, por lo tanto de la misma manera obtendremos los mismos resultados para valores diferentes de X y de Y; a esta probabilidad se le llama probabilidad marginal, y será de gran utilidad en algunos modelos de redes neuronales.
Una de las propiedades de las probabilidades marginales, es que la suma de todos los posibles valores de la probabilidad de la variable aleatoria, será igual a 1, para el ejemplo sería.
\[\large P(X) = P(1 \leq X \leq 6) = p(x=1) + p(x=2) + \dotsc + p(x=6) = 1 \]
.jpg)
\[\large P(Y) = P(1 \leq Y \leq 6) = p(y=1) + p(y=2) + \dotsc + p(y=6) = 1 \]
.jpg)
Finalmente también podemos obtener las probabilidades conjuntas para diferentes valores de X y Y, por ejemplo si quisiéramos obtener la probabilidad de que X obtuviera un valor en cuánto mucho 2 y Y obtuviera un valor en cuánto mucho de 2, seria.
\[\large P(X \leq 2, Y \leq 2) = \sum_{i=1}^{i=2} \sum_{j=1}^{j=2} p(x_{i},y_{j}) \]
.jpg)
Distribución de probabilidad conjunta continua: Sean X y Y variables aleatorias continuas. Una función de densidad de probabilidad conjunta f(x, y), es una función que satisface.
\[\large f(x,y) \geq 0 \\ \\ \large \int_{-\infty}^{\infty} \int_{-\infty}^{\infty} f(x,y) \,dx \,dy = 1 \]
Entonces para cualquier conjunto A en dos dimensiones
\[\large P[(X,Y) \in A] = \int_{A}^{} \int_{A}^{} f(x,y) \,dx \,dy \]
Una forma de verlo de manera conceptual, sería asumir una función de distribución con dos variables conjuntas, cuyo espacio de eventos del conjunto A es un rectángulo definido por {(x,y): a <=x<= b, c<=y<=d}, entonces.
\[\large P[(X,Y) \in A] = P(a \leq X \leq b, c \leq Y \leq d) \int_{a}^{b} \int_{c}^{d} f(x,y) \,dy \,dx \]
Se puede establecer que la función f(x,y) está a una distancia del punto (x,y), y la probabilidad establecida en el conjunto A, será el volumen bajo la superficie definida por la función f(x,y) en el rango definido por el conjunto A.
En capítulos posteriores entraremos en detalle en algunas funciones de distribución de probabilidad, que ayudan a modelar algunos fenómenos físicos reales por medio de ecuaciones compuesta por parámetros para entender mejor el comportamiento de las variables aleatorias asociadas a ciertos experimentos; en este punto es importante resaltar que estos modelos serán las bases o las instrucciones con las que las redes neuronales aprenderan a predecir o gestionar la incertidumbre.
Desing by Vlad Card