Probabilidad I
Qué aprenderás en esta sección
Abordaremos conceptos como variables aleatorias, eventos, teoría de conjuntos, esperanza y varianza que nos permitirán comprender más adelante conceptos como modelos probabilísticos que son de utilidad en aplicaciones de machine learning, en este capítulo comprenderás conceptos básicos de la probabilidad y el concepto en si mismo.
Desarrollo
Que es la probabilidad?
A menudo escuchamos este término en nuestra cotidianidad desde la probabilidad de que llueva, hasta en noticias que hablan sobre la posibilidad de encontrar vida en otros planetas; la probabilidad permea nuestras vidas y es más común de lo que pensamos en nuestra sociedad, es por eso que la mente humana ha tratado de comprender esa incertidumbre de los hechos que nos rodean y de esa manera poder predecir nuestras acciones, sin embargo hasta el dia de hoy, la incertidumbre sigue siendo eso, y no tenemos una verdad absoluta de lo que sucederá mañana.
Un ejemplo usado muy a menudo y que damos por sentado, es que la probabilidad de obtener cara al lanzar una moneda honesta es del 50%, sin embargo qué significa realmente ese número; si lo miramos bajo un enfoque frecuentista es un número que expresa cuántas veces se repite un resultado como obtener cara al lanzar una moneda en un número determinado de lanzamientos.
Para comprender el concepto, supongamos que tenemos una moneda con dos lados, uno lado lo llamaremos “cara” y el otro “sello” y realizamos unos 100 lanzamientos; por cada lanzamiento registramos el valor obtenido en cuyo caso hipotético podríamos obtener lo siguiente.
\[\Large \textrm{c x c x c x c c c x x c x c x c x c x c \\c x c x c x c x x c x c x c x c x c x c \\c x c x c x c c c x x c x c x c x c x c \\c x c x c x c c c x x c x c x c x c x c \\c x c x c x c c c x x c x c x c x c x c } \]
De los resultados contamos cuántas caras y sellos vimos, para un total de 47 caras y 53 cruces, lo que en términos generales se podría decir que si vuelvo a lanzar la moneda voy a tener casi el mismo chance de obtener cara o sello, pues los resultados obtenidos respaldan esa situación.
Como los chances son casi iguales en el ejercicio de 100 lanzamientos tanto para obtener cara o sello, otra manera de expresarlo sería que de cierta cantidad de lanzamientos de la moneda, la mitad de las veces voy a ver cara y la otra mitad voy a ver sello, y como hablamos de mitades un buen indicador sería dividir la unidad entre dos, es decir ½ de las veces obtendré cara y el otro ½ obtendré sello, y de allí sale el 50%; sin embargo siendo estrictos de acuerdo a los datos obtenidos en el ejercicio, realmente la probabilidad de tener cara es del 47% pues se obtuvieron 47 caras de 100 lanzamientos, y la probabilidad de obtener cruz es del 53% respectivamente, sin embargo si pudiéramos realizar indefinidos lanzamientos, eventualmente las probabilidades convergen al 50%.
Por lo tanto, una definición de probabilidad sería el grado de certeza que se tiene de que algo ocurra.
Otro enfoque que tiene el concepto de la probabilidad cuando no se cuenta con datos que permitan inferir de manera frecuentista y en donde prima la intuición o la creencia de que algo tiene cierto chance de que suceda, como por ejemplo los comportamientos de la sociedad, el vaivén errático y caótico de los mercados, el ciclo de vida de una persona o inclusive el comportamiento del clima en el que dependiendo de quién sea el observador la intuición de que sucedan ciertos eventos o no es relativa, y que el método frecuentista a veces no logra describir; este enfoque es llamado probabilidad subjetiva.
Sin embargo en los tiempos presentes, el concepto de probabilidad se define por medio de unos axiomas que postularemos más adelante, antes de ello abordaremos algunos conceptos básicos que debemos tener presentes.
Conceptos básicos
Experimento aleatorio: es todo evento o acción que genera datos que aunque se realice siempre bajo las mismas condiciones o parámetros, el resultado será diferente, por ejemplo plantar dos semillas idénticas en las mismas condiciones y con los mismos cuidados, darán resultados diferentes entre las dos plantas en características como la altura, el número de hojas, flores, etc.
El contraejemplo de los experimentos aleatorios son los experimentos deterministas, los cuales si se realizan bajo las mismas condiciones se obtendrá con un buen grado de exactitud los mismos resultados, ejemplos de experimentos deterministas sería el tiempo de caída de una pelota a cierta altura, el tiempo de viaje de un automóvil de un punto a otro bajo ciertas condiciones y en general todo experimento del que podamos saber el resultado según sus condiciones iniciales.
Espacio muestral (S): es el conjunto de todos los posibles resultados que se puedan obtener de un experimento aleatorio, en el caso de la moneda los dos únicos posibles resultados son cara o sello y por lo tanto el espacio muestral de la moneda expresado en su connotación matemática sería S = {cara, cruz} y en su expresión visual por medio de diagrama de Venn el siguiente, adicional se presentan otros dos ejemplos.

\[ \large \textrm{ S = \{cara, cruz\} }\]
Evento (E): es un grupo de los posibles resultados que se tienen en el espacio muestral, un espacio muestral puede contener varios eventos; los eventos pueden ser simples o compuestos; los eventos simples son el resultado obtenido de ejecutar una vez un experimento, como por ejemplo el obtener cara al lanzar una moneda, obtener un 3 al lanzar un dado o registrar la edad de una persona elegida al azar; los eventos se representan como conjuntos.
Los eventos compuestos son la agrupación de varios eventos simples, como por ejemplo el evento compuesto de los números pares de un dado A = {2, 4, 6} o el evento compuesto de las personas con edades entre 20 y 25 años B = {20, 21, 22, 23, 24, 25}.
A continuación ilustraremos los eventos simples y algunos compuestos para el experimento aleatorio de lanzar dos monedas.
\[ \large \textrm{ espacio muestral = S = \{(cara, cara), (cara, sello), (sello, cara), (sello, sello)\} }\] \[ \large \textrm{evento simple = A = \{cara, cruz\} }\] \[ \large \textrm{ evento compuesto obtener una sola cara = B = \{(cruz, cara), (cruz, cruz)\} }\] \[ \large \textrm{ evento compuesto obtener al menos una cara = C = \{(cruz, cara), (cruz, cruz)\} }\]
Teoría de conjuntos en probabilidad
Como un evento es en esencia un conjunto, entonces se puede aplicar la teoría de conjuntos a los mismos, por lo tanto algunos conceptos que se tienen son.
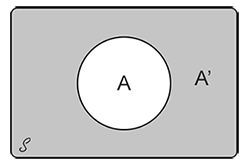
El complemento de un evento A, denotado por A’, es el conjunto de todos los resultados en el espacio muestral S, que no están contenidos en el evento A.
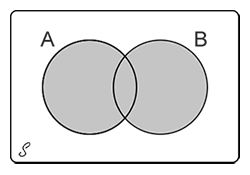
La unión de dos eventos A y B, denotado como AUB, es el conjunto de los resultados contenidos en A o B.
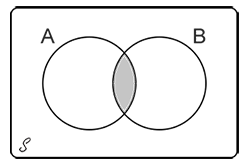
La intersección de dos eventos A y B, denotado como A∩B, es el conjunto de los resultados que se encuentran tanto en A como en B.
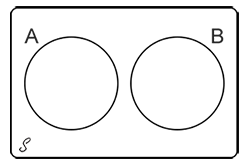
El conjunto vacío, es el conjunto sin resultados, se expresa como Ø; en el caso de la intersección de los eventos A y B sea vacío, A∩B = Ø, se dice que los eventos son mutuamente excluyentes o disjuntos.
Los eventos mutuamente excluyentes son aquellos que no ocurren simultáneamente. Por ejemplo, al lanzar una moneda el resultado será cara o cruz, pero no es posible obtener ambos al tiempo. Estos eventos también se denominan eventos disjuntos ya que no ocurren simultáneamente.
Con estos conceptos básicos ahora se puede abordar los axiomas que deben cumplirse siempre en las probabilidades.
Axiomas de la probabilidad
Los siguientes axiomas definen el concepto moderno de probabilidad. Dado un espacio muestral y un experimento asociado al mismo, la probabilidad de un evento cualquiera denotado como P(A), es un número asignado que representa el chance o la oportunidad de que ese evento suceda, este concepto debe cumplir las siguientes condiciones.
1. Para cualquier evento \( A \), \( P(A) >= 0 \)
2. La probabilidad del espacio muestral S es 1, \( P(S) = 1 \)
3. \( A_{1}, A_{2}, A_{3}, . . ., A_{n} \) es un conjunto de eventos mutuamente excluyentes, entonces
\[ \large P(A_{1} \cup A_{2} \cup A_{3} . . .) = \sum_{i=1}^{\infty}P(A_{i}) \]
Propiedad de la probabilidad
Para cualquier evento \( A \), \( P(A) + P(A^{'}) = 1 \), a partir de la cual \( P(A) = 1 - P(A^{'}) \).
En el axioma 3, \( A1 = A \) y \( A2 = A^{'} \) como por definición de \( A \cup A^{'} = S \) en tanto \( A \) y \( A^{'} \) sean eventos disjuntos.
\[ \large 1 = P(S) = P(A \cup A^{'}) = P(A) + P(A^{'}) \] \[ \large P(A) = 1 - P(A^{'}) \]
Retornando al ejemplo del dado, podríamos definir que el evento A como los resultados pares, y por consiguiente su complemento denotado A´ sería todos los demás resultados que no son pares.
\[ \large A = \{2, 4, 6\} \] \[ \large A^{'} = \{1, 3, 5\} \] \[ \large P(A) = 1 - P(A^{'}) \]
Como ambos eventos son eventos simples y excluyentes, se tiene.
\[ \large P(A) = 1 - P(A^{'}) = P(par) = 1 - P(impar) \]
Cuando dos eventos A y B no son mutuamente excluyentes se tiene que.
\[ \large P(A \cup B) = P(A) + P(B) - P(A \cap B) \]
Obsérvese primero que AUB puede ser descompuesto en dos eventos excluyentes, A y B∩A'; la última es la parte B que queda fuera de A. Además, B por sí mismo es la unión de los dos eventos excluyentes A∩B y A'∩B, por lo tanto P(B) = P(A∩B) + P(A'∩B). Por lo tanto.
\[ \large P(A \cup B) = P(A) + P(B \cap A^{'}) = P(A) + [P(B) - P(A \cap B)] \\\\ \large = P(A)+P(B)-P(A \cap B) \]
Para ilustrar esta propiedad, supongamos que de una población se sabe que el 60% de las personas tienen al menos un perro, el 30% tienen al menos un gato, y un 20% tienen al menos un perro y un gato, y quisieramos saber cual es la probabilidad de que una persona tenga por lo menos una mascota; para ello vamos a dibujar los respectivos conjuntos con sus probabilidades, obteniendo lo siguiente.

Como el valor que queremos hallar es la probabilidad de que una persona tenga por lo menos una mascota, es decir, que por lo menos tenga un perro o un gato, sería la unión de los conjuntos perro y gato PUG menos la intersección de estos dos conjuntos, para lo cual se tiene una probabilidad total de 70%; la cual vista de manera gráfica sería.
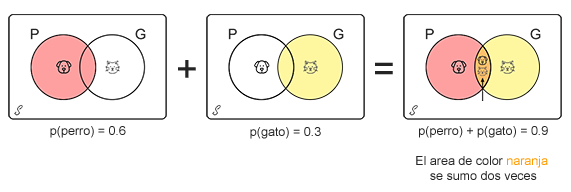
De la gráfica se aprecia que en el resultado de la suma de las probabilidades P y G, se ha sumado dos veces la probabilidad de que una persona tenga un perro y un gato (intersección P∩G), por lo tanto se hace necesario restar el valor de la intersección para poder obtener el valor de la probabilidad de que una persona tenga un perro o un gato.
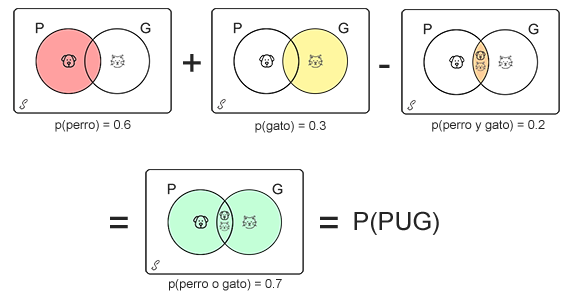
Nota: en el sentido estricto, en los diagramas de Venn no se grafica la probabilidad sin embargo por temas prácticos en el ejemplo anterior se hizo uso el porcentaje de probabilidad para ilustrar mejor la idea.
La razón del porque se resta la intersección, es porque cuando sumamos los conjuntos P y G, estamos sumando dos veces la intersección; otra forma de verlo y que expone lo anteriormente dicho sería por medio de la siguiente ilustración, en donde hemos tomado una muestra de 10 personas y establecido en función de las probabilidades que numero de personas tienen un perro y cuantas tienen un gato.




De la tabla se puede apreciar que de una muestra de 10 personas, 6 de ellas tienen un perro es decir el 60%, 3 de ellas tienen un gato es decir el 30%, adicionalmente también se puede decir que 2 personas de las 10, tienen un perro y un gato es decir el 20%, y finalmente es fácil evidenciar que 7 personas de las 10 tienen un perro o un gato, lo que representa el 70%, y ese era el valor que estábamos buscando y que obtuvimos por medio de la teoría de conjuntos.
Variable aleatoria
Del ejercicio de la moneda se puede observar que solo obtuvimos dos posibles resultados al lanzarla que fueron obtener cara o sello, sin embargo resulta práctico asignar un valor numérico a cada uno de esos resultados, esto debido a que para poder manipular probabilidades con ecuaciones o fórmulas es indispensable contar con una representación numérica de los eventos; para el caso de la moneda, podríamos asignar al evento obtener cara un 1, y al evento obtener sello un 0, o asignar cualquier otro número real.
\[ \large X[cara] = 1 \qquad X[sello] = 0 \]
En general una variable aleatoria es en esencia una función matemática, que asigna a un evento un valor numérico, que pueda representar una característica de los mismos.
Las variables aleatorias se representan por una letra mayúscula usualmente las últimas del abecedario, y sus respectivos valores con una letra minúscula.
En la mayoría de casos y bajo un punto de vista práctico no estamos tan interesados en saber la probabilidad de un evento en particular de un espacio muestral, sino más bien la característica del mismo, por ejemplo, en un experimento de lanzar dos dados, nos interesa por ejemplo saber mas cual es la probabilidad de que la suma de los resultados de los dos dados sea inferior a 5, a que por ejemplo saber la probabilidad de obtener un 2 y un 4 respectivamente.
Otro ejemplo que ilustra el concepto de variable aleatoria sería suponer que tenemos una bolsa llena con 3 tipos de balotas de diferente color, amarilla, azul y roja; el experimento consistirá en sacar una balota, registrar el color obtenido, volver a introducir la balota en la bolsa, mezclar de nuevo las balotas, sacar otra balota, registrar el color obtenido y volverla a introducir.
Por lo tanto del experimento se puede decir que existen en total 9 posibles resultados que podemos obtener, los cuales definen el espacio muestral de la siguiente manera; por practicidad asignamos una letra a cada color es decir, amarillo sera “y”, azul sera “b”, y rojo “r”.
\[ \large S = \{(y,y), (y,b), (y,r), (b,y), (b,b), (b,r), (r,y), (r,b), (r,r)\} \]
Cada uno de los eventos que componen el espacio muestral son eventos simples, pues son el resultado de una acción del experimento.
De los posibles eventos simples que se pueden obtener del experimento, queremos establecer el evento compuesto que agrupe todos los resultados en los que se obtuvo solo una balota amarilla, ese evento sería el siguiente.
\[ \large \textrm{ A = \{resultados en los se obtuvo una sola balota amarilla\} } \] \[ \large A = \{(y,b), (y,r), (b,y), (r,y)\} \]
Análogo, también se pueden generar un evento compuesto por los resultados en los que se obtuvo exactamente dos balotas amarillas, que sería.
\[ \large \textrm{ B = \{resultados en los que se obtuvo dos balota amarilla\} } \] \[ \large B = \{(y,y)\} \]
Los anteriores eventos compuestos, se pueden representar por medio de una variable aleatoria X, la cual se definirá como la cantidad de balotas amarillas que se pueden obtener en el experimento, es decir.
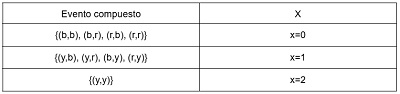
Por lo que.
\[ \large X[x=0] = A \] \[ \large X[x=1] = B \]
E inclusive se pueden obtener más eventos compuestos como por ejemplo, el evento en el que se obtuvo por lo menos una balota amarilla.
\[ \large X[x \leq 1] = \{resultados \hspace{0.3em} en \hspace{0.3em} los \hspace{0.3em} que \hspace{0.3em} se \hspace{0.3em} obtuvo \hspace{0.3em} por\hspace{0.3em} lo\hspace{0.3em} menos\hspace{0.3em} una\hspace{0.3em} balota\hspace{0.3em} amarilla\} \]
En donde cuando procedemos a calcular las respectivas probabilidades podemos representarlas de las siguientes maneras.
\[ \large \textrm{ P(A) = P\{de obtener una sola balota amarilla\} } \] \[ \large P[X=1] = P(A) \]
Como se observa, se puede representar la probabilidad de maneras diferentes, sin embargo por cuestiones prácticas, el uso por medio de variables aleatorias será el común cuando abordemos los modelos probabilísticos.
Variable aleatoria discreta: Estas variables se caracterizan por contener eventos que son de índole discreta, es decir que entre dos evento simples solo se puede presentar un número finito de posibles valores, como por ejemplo, el número de hijos en una familia, el número de lados de un dado, el número de productos averiados o no, es decir eventos que no pueden ser subdivididos.
Variable aleatoria continua: Estas variables se caracterizan por contener eventos que son de índole continua, es decir que entre un evento y otro pueden existir infinitos eventos, ejemplos de ello pueden ser medidas de estatura, pues entre una estatura de 150 cm y 151 cm hay infinitos valores como 150.1, 150,11, 150.12, etc.
Variables independientes e idénticamente distribuidas (i.i.d., iid o IID): Este término significa que el resultado de un evento no afecta los siguientes, por ejemplo, lanzar una moneda y obtener cara, no afecta el resultado del próximo lanzamiento, pues la probabilidad del próximo lanzamiento seguirá siendo la misma independientemente si en un lanzamiento previo obtuve cara o cruz; en el siguiente ejemplo se podrá apreciar mejor el concepto de independencia.
Supongamos que tenemos una bolsa con 5 balotas rojas y 5 balotas azules y sin posibilidad de ver el contenido de la bolsa; sacamos una balota, la volvemos a introducir, mezclamos bien y volvemos a sacar otra balota; la probabilidad asociada de sacar una balota de un color u otro es la misma cada vez que introducimos la balota que sacamos, pues no estamos alterando la cantidad de balotas que hay al interior de la bolsa por cada iteración y por lo tanto cada evento es independiente del anterior y las condiciones iniciales se mantienen.
Sin embargo si tenemos la misma bolsa con las mismas balotas, pero en este caso cada vez que sacamos una balota no la reintegramos a la bolsa; la cantidad de balotas al interior se ve disminuida por cada iteración y allí las probabilidades empiezan a cambiar en función de la cantidad de balotas que tengamos en la bolsa, en este caso la variable aleatoria es condicionalmente dependiente.
Esperanza o valor esperado
Es el promedio de los eventos ocurridos o predichos, su expresión es la siguiente.
\[ \large E(X) = \mu_{x} = \sum_{x \in D}^{}x \cdot p(x) \]
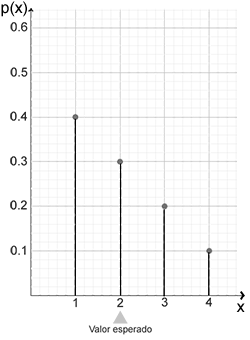
Para ilustrar el concepto de esperanza o valor esperado, supongamos que somos dueños de una tienda de productos tecnológicos, y decidimos registrar por un año qué cantidad de artículos compra un cliente, para un total de 1000 artículos vendidos en el año, obteniendo los siguientes resultados.
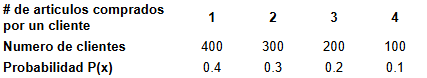
Los valores de las probabilidades tabulados, se obtuvieron en función de la cantidad de clientes por cada categoría, es decir como 400 clientes de los 1000 registrados realizaron una sola compra, equivale a una probabilidad del 40%, de esta misma forma se obtuvieron las demás probabilidades.
De la información registrada deseamos saber cual es el valor esperado del número de artículos que un cliente podría realizar en su compra; para ello aplicamos el concepto de valor esperado obteniendo lo siguiente.
\[ \large E(X) = \mu_{x} = \sum_{x \in D}^{}x \cdot p(x) \\\\ \large = 1 \cdot p(x=1) + 2 \cdot p(x=2) + 3 \cdot p(x=3) + 4 \cdot p(x=4) \\\\ \large = 1 \cdot 0.4 + 2 \cdot 0.3 + 3 \cdot 0.2 + 4 \cdot 0.1 = 2 \]
El valor resultante es el número de artículos que se espera que un cliente realice en su compra.
Varianza
Para comprender el concepto de varianza, vamos a exponer dos ejemplos en donde el valor esperado es de 2, tal y como se muestra a continuación.

La diferencia entre ambos ejemplos es que los valores de la gráfica de la izquierda están más dispersos que los de la derecha, y allí es donde entra el concepto de varianza que determina qué tan dispersos están estos valores con respecto al valor esperado.
Con lo anterior aclarado, la expresión para calcular la varianza es la siguiente.
\[ \large V(X) = \sigma_{x}^{2} = \sum_{D}^{}(x-\mu)^{2} \cdot p(x) = E[(X-\mu)^{2}] \]
Desviación estándar
Al igual que la varianza la desviación estándar es una medida de la dispersión de los valores de las probabilidades, la cual se deriva directamente del valor de la varianza, siendo su expresión matemática la siguiente.
\[ \large \sigma_{x} = \sqrt{\sigma_{x}^{2}} \]
Variables aleatorias conjuntas
Algunos experimentos aleatorios pueden estar compuestos de otros experimentos, por ejemplo tener dos dados y considerar que cada uno es un experimento individual, o tener dos máquinas que fabrican cierto producto donde cada una puede ser un experimento independiente que cuyas eventos será si el producto esta en buen estado o no, y así para cualquier experimento que pueda estar compuesto por dos o más experimentos; para estos escenarios al tratarse de experimentos individuales cada uno de ellos tendrá asociado su propio espacio muestral y su propia variable aleatoria, en algunas ocasiones los experimentos son más fáciles de tratar cuando se subdividen en dos o más experimentos pudiendo llegar a los mismos resultados que si se abordara como uno solo.
Para comprender el concepto vamos a tomar dos dados, los cuales llamaremos dado 1 y dado 2, el experimento aleatorio de lanzar el dado 1 tendrá su propio espacio muestral definido como S1 y su propia variable aleatoria X que describe el valor observado en el dado; análogamente para el dado 2 tenemos un espacio muestral S2 y una variable aleatoria Y.
Para este ejemplo en particular podemos decir que los dos experimentos son físicamente independientes, es decir, al ejecutar el experimento del dado 1 su resultado no afecta el comportamiento del dado 2 y viceversa, esta condición es importante pues en caso de que los experimentos fueran físicamente dependientes, el análisis para dos o más variables conjuntas no cuenta con resoluciones aun.
Entonces bajo el argumento de la independencia física y considerando que ambos dados son honestos, es decir que cada cara tiene la misma probabilidad de salir, se tienen los siguientes espacios muestrales.
\[ \large S_{1} = \{1,2,3,4,5,6 \} \] \[ \large S_{2} = \{1,2,3,4,5,6 \} \]
Aplicando el concepto de la variable conjunta para el experimento comprendido por los dos espacios muestrales de los dados 1 y 2, se define el siguiente espacio muestral.
\[ \large S = \{(w_{i}, t_{j});\hspace{15px} i=1,2,3,4,5,6;\hspace{15px} j=1,2,3,4,5,6 \} \] \[ \large S = \{ (1,1),(1,2),(1,3),(1,4),(1,5),(1,6),\\ \large (2,1),(2,2),(2,3),(2,4),(2,5),(2,6),\\ \large (3,1),(3,2),(3,3),(3,4),(3,5),(3,6),\\ \large (4,1),(4,2),(4,3),(4,4),(4,5),(4,6),\\ \large (5,1),(5,2),(5,3),(5,4),(5,5),(5,6),\\ \large (6,1),(6,2),(6,3),(6,4),(6,5),(6,6), \} \]
El cual está compuesto por cada par de valores posibles de los dos espacios muestrales, por lo tanto la variable aleatoria conjunta para este nuevo espacio, sería la siguiente.
\[ \large (X,Y) = \{(x_{i}, y_{j}); \hspace{15px} i=1,2,3,4,5,6; \hspace{15px} j= 1,2,3,4,5,6 \} \]
El ejercicio anterior corresponde a un caso discreto, sin embargo el principio es el mismo para el caso continuo.
El concepto de variable conjunta es muy relevante para cuando empecemos a trabajar con redes neuronales generativas.
Desing by Vlad Card